
The olden times
Did you know that the original name for SQL (Structured Query Language) whas SEQUEL, acronym for "Structured English Query Language"? The original intent was to design a way to access data in a 1970's integrated relational data base system. Another intent was for it to be as similar to spoken English sentences as possible so that non-technical personell, i.e. accountants, architects, etc., could use it to dig through the database system directly from mainframe-connected terminals sitting on their desks. Or, in the words of its creators: "SEQUEL is intended as a data base sublanguage for both the professional programmer and the more infrequent data base user."
SEQUEL was "[...] intended to simplify programming for the professional and to make data base interaction available to a new class of users [...] There are some users whose interaction with a computer is so infrequent or unstructured that the user is unwilling to learn a query language. For these users, natural language or menu selection seem to be the most viable alternatives. However, there is also a large class of users who, while they are not computer specialists, would be willing to learn to interact with a computer in a reasonably high-level, non-procedural query language. Examples of such users are accountants, engineers, architects, and urban planners. It is for this class of users that SEQUEL is intended."
That is a quote directly from the year of 1974.
I like to think of SQL as one of many steps on that path that information technology professionals took to get to the point where the "more infrequent ... user" can use an information technology system by a sole means of spoken words. Achieving that would be a realization of the ultimate human-machine interface dream: simply speak clearly into this box over here, please, and it will do what you tell it to. No need for obscure technical knowledge, or extended training, or participation medals, just an average, infrequent user telling the box what they want, and the box obeys.
Some argue that the dream is already realized, it's done, it's here, your task is to just learn how to properly use the... wait. Isn't the whole point to NOT have to go through extensive training to become a Certified Professional on how to use a human-machine interface? Or a universal generic intelligent technology?
While some like to argue with their arguments in an argumentative way, I like to exercise my Pragmattic Programmer persona: let's look at this in terms of what works now and how we can use it to get consistent results that are useful for whatever our endeavour may be.
Let's talk a little bit about LLMs.
A caveat: distilling any complex topic to a few paragraphs or sentences, let alone a three word slogan, will always be an impossible task. We still do it because the point is not to replace the entire sea of knowledge with a spoon of select drops of water, the intent is to give a few clear pointers, to draw a simple map, to carve a less burdensome trail, to put together a makeshift tool, that will allow one to navigate the jungle, and to serve as a conceptual seed to crystalize more comprehensive and deeper knowledge about... well, the jungle.
In other words, if you just came up with a gotcha on how this or that in this article is aktshually not like that (including how to spell the word "acktshually"): I don't give a flying goose. Also, re-read the previous paragraph.
OK, let us begin, shall we?
You have 100% guaranteed already heard people using "next token predictor", "autocomplete on steroids" and similar expressions to describe in a few words, almost certainly in a demeaning manner, how LLM works or what it does. While the "next token predictor" is not wrong, it's technically correct, and "autocomplete on steroids" won few critical acclaims for its ability to paint vivid pictures of LLM internals, these catchphrases don't really help us in practical ways. For example, if you want to figure out how an existing system that includes an LLM works or what it does, or you want to design or just quickly put together one, these phrases, while correct, don't really offer much help. There is a giant chasm between "it predicts the next word" on one side and on the other the text you are looking at, text that came out as an answer to the question you just asked your favourite chatbox. "But wait, it understands me!!"
I'd like to offer a differrent catchphrase, one that, the hope is, may prove to be much more useful than most, if not all, the other ones you've heard so far. It is in the title:
"The Magnificent Translation Machine".
Hear me out.
Translating languages
The process of translating one language to a different one can be dismissed as fairly simple or, to use the explanation I've heard recently from someone who waived their hand dismissively, probably thinking they've nailed it: "it's just replacing one word with another". In very general terms, it is a process of replacing words of one language with words from a different one, with goal being to arrive at a sentence in that other language that tells the same story as the sentence from the first language. There are some minor difficulties that stand in a way of creating the perfect foreign language translation automata however, and human people have been studying those difficulties over the past centuries finding solutions to them with varying success.
Let me give you a few examples.
English language has this thing called definite (or determinate) and indefinite (or indeterminate) article, namely words "the" and "a"/"an". You may object to qualifying those as words, keep in mind though that for a tranlation automata they are words, or maybe a bit more accurately, units of translation that are as important as any other unit of translation (a.k.a. word). It has to do the work regardless of your view on what constitutes a word or not. Some languages do not have definite article, like for example, Ukrainian language. And there you have it: a fairly trivial case where "just replacing words" approach falls apart. Add to that that some other languages, like Spanish, have more than one form of definite article ("el", "la", "los", "las"), and then add to that yet some other languages which, like German, have definite articles in a form of a suffix, meaning the article is not a word of its own but it is part of the word that it marks.
There, a very simple case where a translation automata has to either add new units of tranlation (words) or remove them, or even choose one specific appropriate form of a word, in case where the article is a suffix.
Why am I using term "automata"? Keep reading.
Next example of how translation from one language to a different one is not as fairly simple as it may at first seem is when you are translating between languages that order words differently, a good example would be translating French to English, and vice versa. French "Agence spatiale canadienne" translated to English is "Canadian Space Agency". Word-for-word, sure, but in opposite order. Also, capitalization.
Yet another example of translation hurdles is when you have to replace one word in one language with two or even more words in a different one. Or two word phrase with a three word phrase that will completely break and lose its meaning if you just do word-for-word replacement.
And yet another example is when you have to use the same target language word for different source language words, depending on what the sentence is about, because one word in a language can have different meaning (i.e. refer to different things or actions) depending on context, where a different language may use distinct words, which use of does not depend on context.
I will stop with examples of exceptions to the "just replace words" approach here for two reasons:
- There are just so many of exceptions to that approach, and
- The examples I chose are not random, I'll use them to paint the picture behind "The Magnificent Translation Machine" mental model of your favourite LLM.
OK, let's summarize...
Language translation, in a handful of words
So, language translation is definitely not a trivial, or even somewhat simple, process. It is however, a fairly closed-ended task: the result should have as close of a meaning to the original language as possible, which, among other things, means you are limited with what (i.e. which words) gets generated as output from translation, as well as how much of it gets generated. French sentence translated from an English one should be exactly one sentence, with number of words that are very close, if not equal, to the number of words in the sentence that is being translated, and the choice of words is pretty straightforward and determined by what is being translated from.
Here is a list of language translation process characteristics, all of which are purposefully picked to support the image I'm painting here in order to illustrate what the concept of "The Magnificent Translation Machine" is:
- translation will generate about the same amount of text as however much can be found in the input
- translation may expand a little bit the output to contain more words than input, i.e. definite articles in target language
- translation may contract a little bit the output to contain less words than input, i.e. there are no definite articles in target language
- translation will have to reorder corresponding words in output to match target language ordering rules for a sentence
- translation has to be able to take the context (what other words are around this one and where) of the word into account, in order to determine which word to choose to output, from possible multiple choices, depending on the surrounding words
Let's play with some words using Google Translate to convert English words to German words and vice versa. Also, if you point your finger and say something along the lines how those are not proper English or German sentences, I will slap you with a fresh homemade blueberry pie straight in the face for not paying attention in class.
Let's start with:
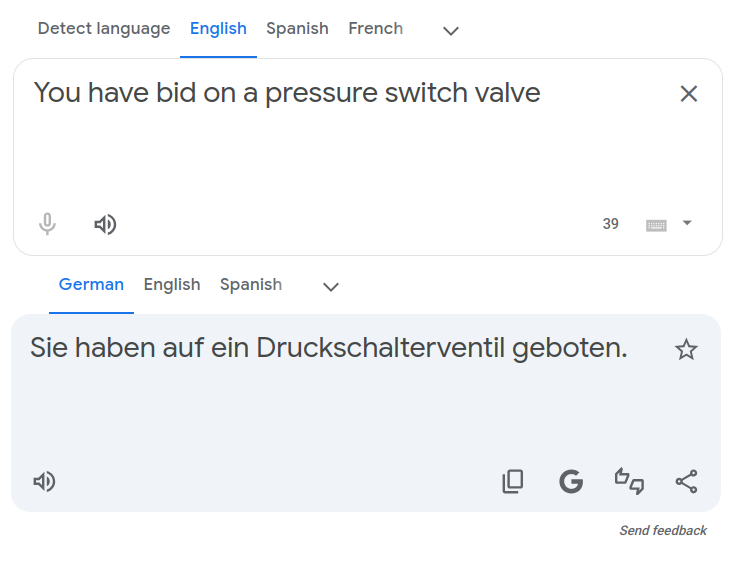
and then change "bid on" to "bought". German translation changes two words ("auf" is removed, and "geboten" becomes "gekauft") in different places:
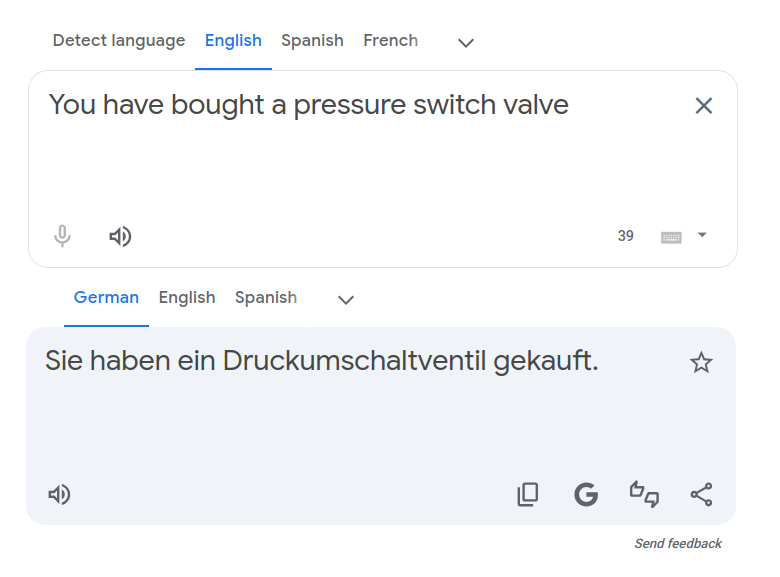
Switch languages around and play with deleting and reordeing German words:
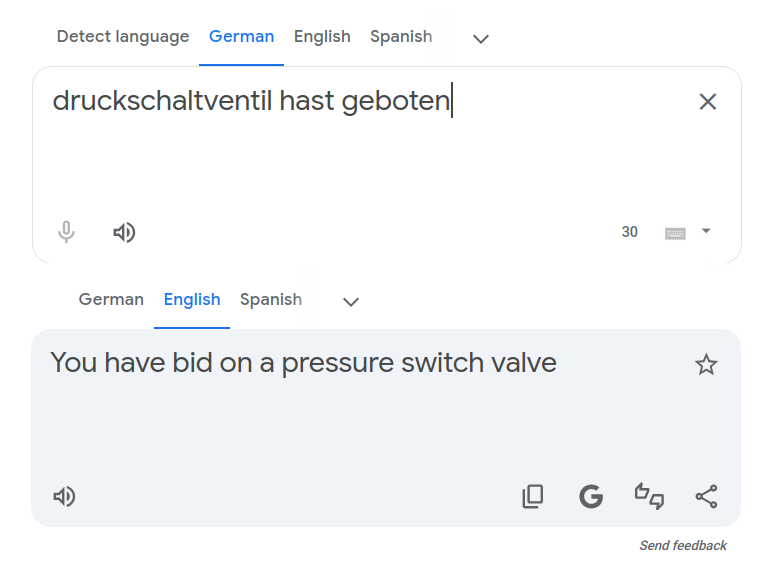
Double-down on "hast" with "du hast" and you get an English Yoda-like response:
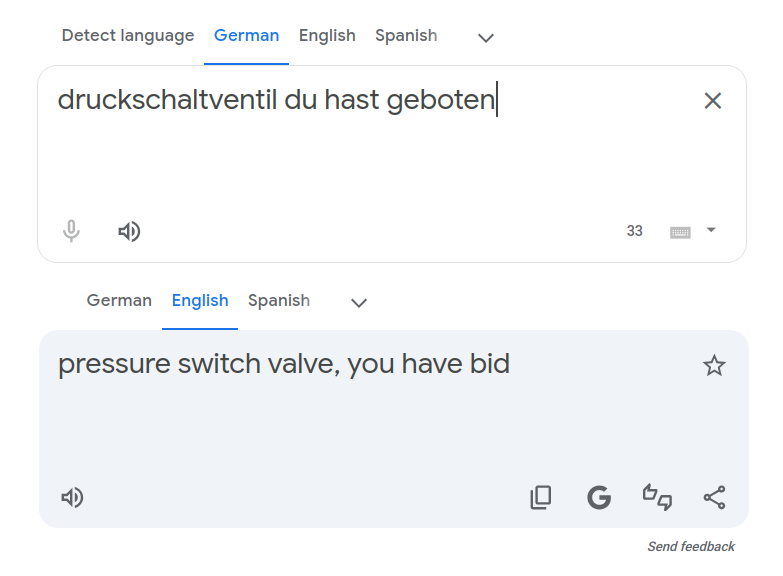
Switch languages around and it's a bit more "proper" German Yoda:
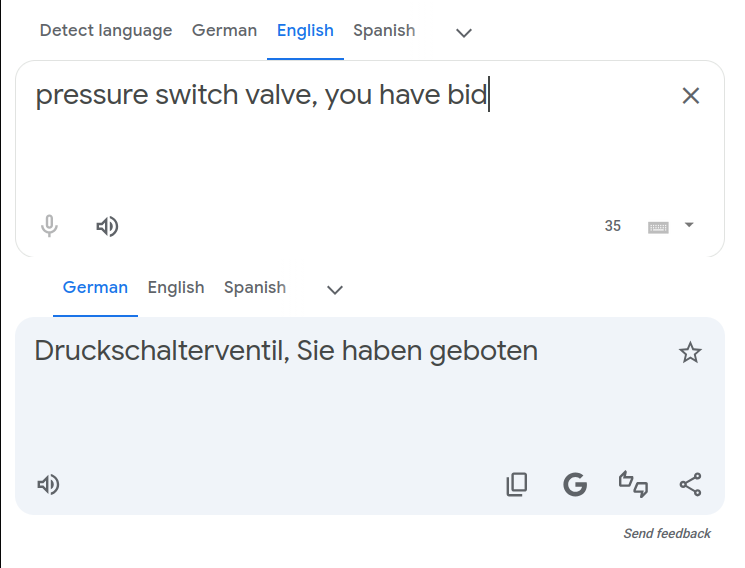
Change order of German words in the "du hast" example and the automata makes a better English sentence:
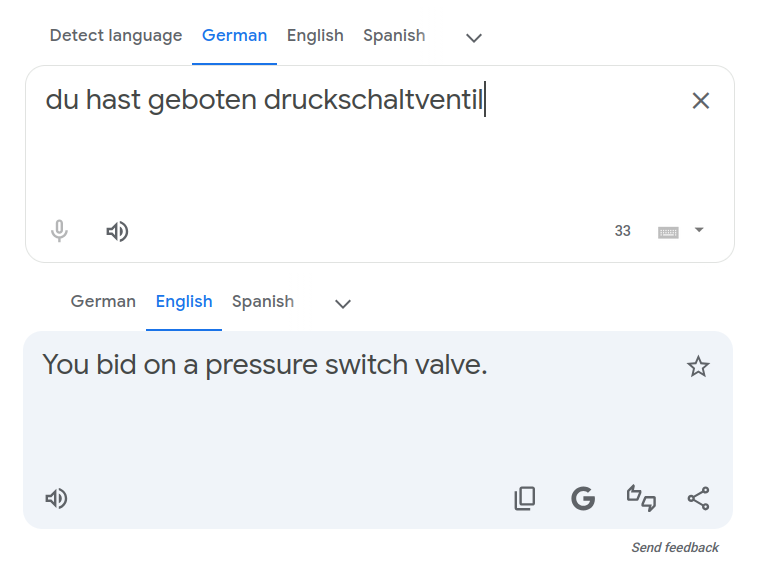
While not all of the examples are a proper use of English or German language, if you are an English or German speaking person, you can either straight up understand what the sentence is saying or you can pretty much with 100% certainty understand what is meant by the word salad you are looking at. Which means the translation automata did a fairly good job, with a little bit of your help in a form of headscratching, immediately followed by: "Oh! I see".
Now, what would happen if you wanted to translate from one language into that same language, like English to English, Scots to Scots? Well, that's...
How large language models work
Mind you, that's Large Language Models.
Languages have been studied since the proverbial dawn of humanity, but I'll limit my scholarly expedition into linguistic history to about-ish 1990's when Statistical Language Models were all the scream (I put all those words in this sentence for sole reason that I find them funny, in no particular order). You may or may not have seen at least one someone demonstrating the "let's build an English sentence by choosing the next most statisticaly probable word that would come after this word" method. Statistical Language Models were doing more than that, there's a bunch of calculus and other fine things, but let's just say that that is the gist of it.
Next jump forward was when so-called "neural networks" were incorporated into language modelling. Yes, let's be honest here: they're not neural and not even networks, it's matrix calculus, but that doesn't sound as fancy, and so marketing won that one (again). Neural networks were not just to capture elusive language patterns, but the matrix-vector calculus (which the "networks" are) brought a number of useful methods, including similarity vectors. You know, the things you put into your "vector databases" in order to improve your LLM performance and all that good stuff. People played with that way back in 2000's.
About a decade later, Recurrent Neural Networks (RNNs) became all the latest scream of fashion and the RNN variant called Long Short-Term Memory entered the stage, promising to address problem of relating one (current) word to other (previous) words in a text being processed. Shortly after, Attention Mechanism was invented which was a resounding success when it comes to relating context to a word and word to a context, which in turn, as you might suspect, helps immensely with choosing the proper next word for generated text.
And then, a few short years later, the Transformer was invented.
Arguably, the main advantage of the Transformer model architecture was that it ditched RNNs (recurrent) and CNNs (convolutional) completely and provided more flat structure using only feed-forward networks, with one big advantage: doing back-propagation (a.k.a. "training") was way less compute intensive than if you used CNNs or, gods forbid, RNNs. This meant that you could either train a model on the same amount of data way, way faster, or you could use much more data to train the model in the same amount of time as with CNN/RNN.
Anywho, half a decade after Transformers, at the start of 2020's, GPT and BERT were born, and here we are today. You may or may not have read that needy attention paper, and if you haven't, you can just check its abstract where, after short intro of the technology they came up with, the first thing mentioned they experimented on to evaluate performace was... wait for it... machine translation tasks.
The other one was constituency parsing, which is, according to this article you are reading, technically a form of translation: the model needs to output smaller amount of text, or just one word, that matches the input text in some way. Generating a summary of an email is producing (much) smaller amount of text, the summary sentence or paragraph, from the larger one, the email. Then, if we human people read the summary and then read the email, and go: "hey, this summary matches pretty well with what's in the email!" we then say that the model has a good "comprehension" of text.
I suggest you take a moment to (re)think about that paragraph a bit.
OK, so, that short history exposé up above is there just so that I can say (and also look smart to the uninitiated) that all of those technologies and architectures, up until today, are essentially language translation models.
Now, if you know anything about anything, you will say that that sentence is a pile of duck droppings. There's way more in there than just linguistic translation! And you would be right. However, I am not just right in saying that they are essentially language translation models, I am also techincally right, which takes precendence over any other right, so I win! Right?
First of all, let me remind you of the second paragraph under the section of this article titled "Let's talk a little bit about LLMs". That's correct. Not a flying goose.
Second, let me elaborate.
The language translation process I described earlier, and illustrated with some cheeky examples, has some constraints imposed on it which must be satisfied in order for it to be useful and to be called a working piece of software. The most obvious one is that, for a given source language sentence/words, it has to produce a correct sentence/words in the target language, every time, and the output has to be the same for the same input, every time. That's a big constraint. And while the language translation automata can, as we've seen, create variable output (it's not a naive word-for-word replacement), in other words it can expand or contract a bit output text compared to the input, or reorder generated text somewhat but always in very constrained ways, that variable output is always directly related to the input and will alwyas be the same for the same input.
That is almost like a clockwork mechanism, not a simple one, but a quite complex one, that you give an input to and it produces an output always very closely consistent with the input, as if it is an automata of some sort, if you will. That is why I called it the translation automata.
In contrast, LLMs are translation machines. "Translation" because they essentially do language translation, and the reason they do translation is because the underlying technology is built and designed for natural language translation tasks. Not for simulating thinking or reasoning, or implementing algorithmic tasks, or Boolean logic, but for natural language translation tasks. And there's a big difference there.
Similar to how computers are designed to do numerical computations, LLMs are designed to do natural language translation. While it may not be obvious that you can do much with a machine that does numerical computations really fast, so it may not be obvious that you can do much with natural language translation machine. Not automata, machine.
This article is not titled "The Magnificent Translation Automata". So let's talk about the machine a bit now.
The translation machine still works in the same way as the automata. It has to, because the underlying architecture is designed to do translation, with a number of key differences:
- LLM can produce the same (or very similar) amount of text as the input, but it doesn't have to match words, it can mix-replace-and-match (let's call this a conversation mode)
- LLM can produce quite expanded output, not just a little bit, but it still has to choose words and to string them together so they match the input in some way (let's call this a generative mode)
- LLM can produce quite contracted output, not just a little bit less words than the input, but these still have to be words that are closely related to input text and preferrably be the words that are related to significant words in the input (let's call this a summary mode)
- LLM can reorder output, not solely to match rules of the target language anymore, but in any way related to the input that is still coherent and consistent with the input
- LLM has to be able to take into account context of a word or words it is expanding/contracting/generating new ones for, but not just immedaite or short context, the context has to extend to the entire input text and it has to be targeted to specific sections of the input text depending on which word is being produced in the output
So, in order to make the translation machine work for translation with the same source and target language, i.e. from English to English, we need to relax the proverbial dials, the rules, of the translation automata. And with these very relaxed dials we can do way more and quite different tasks with this machine, than we can with the automata.
Nevertheless, it is still a translation machine.
It's easy to fall into a shallow hole of thinking how translating words of one language to a different one is not the same as coming up with answers to your questions. We humans are the ones who give meaning to things around us, and while we can give different meaning to different things, we can also give different meaning to the same thing depending on a number of reasons. Machine doesn't "know" the difference, it just munches on whatever goes in and cranks out bits and pieces in specific order. You and I then give the meaning to both input and output that goes into the machine, as well as the overall "what the machine is doing": in one case it is language translation, in the other it is conversation, both done by the same machine.
Oh, wait. You didn't know that LLMs are also super good in translating languages? Anecdotally so good, that human translators are saying it is super tough these days to find work. I'm not surprised, because that is what LLMs are: translation machines.
Wait, what did you say? Generating code in a programming language based on text you typed in Spanish is not a translation task? Oh, ye of feeble attention span!
Computer programming languages are also languagues: they're designed as a human-machine interface and based on rules of natural languages, they have syntax and semantic and the normal form and all that good stuff: in other words, a perfect case for a translation machine to translate to or from. The same goes for any structured data: JSON, web pages (HTML, CSS) etc. When the machine translates from natural language into programming language we call that coding, and when it does the opposite, we call it... what? Analysis? Finding bugs? Explaining how code works? Whatever you call it, having a narration in a natural language of what a piece of code does beyond just the simple "...and then it adds 1 to this value..." can be very handy. And it is essentially translation from a programming language into a natural, or human, language.
OK, enough of that. This article is already way longer than I thought it would be, so let us quickly skim over on...
How to use all of this irl
What this article is about is that a large language model is not doing processing, it's doing translating.
Now, that may not seem like much. Keep in mind though that you can also correctly say that computer is "just a collection of 1's and 0's" (correct but not useful at all) or that it "uses Boolean algebra to process data" (correct and a bit more useful) or that it "represents everything as numbers and does the work by clever number manipulation, where the clever part is humans writing instructions on how to manipulate the numbers" (correct and much more useful).
And while LLMs are "just the next word predictors" they are also "translation machines", and thinking of them in terms of translation machines with the above mentioned list of charactheristics in mind (expansion, contraction, conversion, reordering, context) may just prove to be a helpful tool when you are designing your next "AI-driven product" or trying to figure out what can be done to improve on whatever AI workflow you currently have etc.
Just sayin'.
To summarize the most important of what LLMs do, they:
- create shorter version of what goes in, a.k.a. summary
- create longer version of what goes in, a.k.a. answering question, generating email etc
- reorder parts of expanded or contracted output
- change what goes into output based on context, i.e. changing one word in the same sentence can yield slightly or drastically different results
- create a translation of the input: generate HTML, programming code, 3D object modelling files, CNC code (G-code), snippets of text/code etc
All of these operations can't go on for arbitrary long amount of text, for example translating a sentence into longer text (i.e. answering a question) will eventually turn into incoherent blabbering, and at what point that will happen (i.e. how long text it can generate that is still coherent and relevant) depends on the model, but it will eventually happen.
With that list of operations that the translation machine can do, let's look at just a couple of, not entirely randomly hand picked, examples of interaction with LLM, and see where the above mentioned translation patterns appear.
First, here is one where LLM answers a question. This is taken from Rick Beato's "if 65yr me can do this, so can you" video, because I'm lazy to ask an LLM myself:

First thing I want to say is that no human being would answer your question like that: "Here is a 1-day London itinerary that comfortably fits... blah, blah, blah", but a machine that is translating whatever you type into an expanded text would. I added a few annotations to the image to point out to translation patterns.
You may look at this and ask: yes, but how did it know to put that summary bit there, right where it fits, and to add just those proper parts, and create bullet points and event add "(approx. 75-80 GBP)" and all that, it must be thinking in some way! I will genty turn your attention to the section titled "Translating languages" and note that all those questions can be legitimately asked when you look at what the translation automata produces. We don't ask them though, because "it's just replacing words" whereas we call the Beato's example "artificial intelligence". You, my lovely human person, is the one who gives different meaning to the same (or in our case, quite similar) thing that appears in different environment.
My intent is to invite you to take another look at that same thing and use the mental model I'm describing in this article on it and see if using it can produce more useful practical results.
Next, you have already heard how LLMs are super good at coding, building software from scratch and all that, right? Cloudflare did that vibe-coding stunt at the start of 2026 where they had LLM code replacement for Next.js and a lot of people went wild saying that that's it, we are all cooked. Or something like that, don't take my word for it, not paying too much attention to those kind of things.
So, LLMs are thinking, skilled machines, an artificial intelligence sitting in a jar in some data center, just waiting for you to tell it what to do? Or, and pardon me for shilling my own view in my own article about said view, are they a translation machines, hm? If you look at the mentioned Cloudflare article, you may notice the section titled "Why this problem is made for AI" where they highlight the following points:

and

and

and

To summarize that for all of us: if you want to do what Cloudflare did in their coding project, you have to spend thousands of mythical human-hours to:
- create extensive documentation
- build a massive database of specification in the question-answer form (Stack Overflow) and train the LLM on it to embed it into it
- create complete API for your project and train the LLM on it to embed it into it
- create an elaborate and detailed test suite upfront
and you also have to pick support tooling very carefully (they mentioned Vite) so it does the heavy-lifting of whatever you don't want the LLM to spend time on, and only then you pick a proper LLM ("The models caught up" part) to do... what exactly?
You say what you think is the answer to that little question, and I'll say mine (take a deep breath): to translate the documentation (human language) into code (programming language) where the generated translation text is based on the APIs and answer/questions embedded into the LLM through its training data, in addition to being based on training on unrelated examples of code in the same way translation automata is trained on pairs of i.e. English/Spanish translations that are not directly related to your translation request but will be used to generate that Spanish sentence that matches your English input (aaand breathe out). And, to not forget, as the LLM is generating code, the feedback input (additional input text intended to direct what is generated by LLM) to the next iteration is created based on the results of that elaborate and detailed test suite being ran on the code generated in current iteration. That's the "agentic" part of the whole dance routine.
Notice how there's a lot of not really hidden, but also not really much talked about, human work that had to be done up front, in order for the LLM to finally do that thing it does so good: translating from human language sentences to programming language sentences.
Anthropic did a similar stunt to this one, at almost the same time: they had an LLM wrapped into an automation scaffolding (a.k.a. "an agent") build a C compiler "from scratch". If you read the article it quickly becomes obvious that they did the same thing Cloudflare did: used tens of thousands of human-hours of work that was done upfront (documentation, tests, Q/As, all the same jazz), built a harness around it (also done by a human engineer) and then had LLM do the job that it is built to do: translating human language sentences into programming language sentences.
Having both of those examples in mind, I look at my project(s) and ask myself: is it really 16 agents, 2,000 sessions and $20,000 in API costs that's all I need to do to bring that software I have in mind to life? Or do I also need to do all that human work that's been done upfront: create super detailed documentation/specification, give a ton of examples of how my project should work in a form of question/answers, code an absolute whale of tests that cover all the possible use cases for my library/code/project? I mean:

is what Anthropic ppl said in that article too.
It is easy to get excited and carried away when you hear about these kind of feats, but you forget to take into account all that upfront work done by thousands of human engineers that don't work at Cloudflare or Anthropic. All I'm saying is: if you want to do the same thing for your enterprise projects and have similar outcome to what Cloudflare and Anthropic claim to have in these examples, you better take a good look at all the aspects of using LLMs to do the work, not just the fancy ones. Scooping up an open source documentation for open sourced project is one thing, creating an equivalent (which is a must if you want to do the same) for your next big enterprise software killer SaaS project is a different pair of shoes. Not to mention all those thousands of high-quality, super specifc, very detailed tests you need to code before you unleash LLM to do its thing.
What was that? Claude (or whatever the marketing department named it) will to that part too? You really are not paying attention, do you?
Now, starting a massive project from scratch is an extreme example, and that one lies on one end of the spectrum of examples of tasks you can do with the translation machine. On the other end of that spectrum of examples would be starting a coding project with "Build me todo web app" as an input and then accepting whatever comes out as an output, no questions asked. I'm using extreme examples here on purpose. It's much easier to illustrate novel concepts by using extreme examples. Your project, or anything else you want to use an LLM for, lies somewhere in between these two extremes. The key point is the same though: all of the examples, concepts, tools, applications, systems, agents, whatever, that have "AI" in its name, work under the same assumption which is that an LLM is "thinking", "reasoning", "processing", "figuring out", "working on" whatever you think the problem to be solved is.
Cloudflare people say so:

Anthropic people say so:

and pretty much anyone out there that does anything with LLMs is working under the same mental model: that it is an artificial intelligence, a thinking machine of some sort that understands in some machine way of its own what you are typing as an input, and if the output does not correspond well to what you typed as an input, then you need to fix your input typing skills or wait for the next generation of LLM.
Let me say this again: what this article is about is that a large language model is not doing processing, it's doing translating.
It's a different model of reasoning (oh, pun absolutely intended) about LLMs that, my hope is, just might help you build better products and processes while spending way less on tokens, or whatever the pricing unit of usage is these days.
To summarize nicely (hah! another pun, totally on purpose) all of the above, let me cite my good friend and a brilliant enterprise architect Jase: "Hot take: AI is good at writing code, but it is not good at coding". In other words, it's a translation machine, it is not a thinking machine.
What I'm describing here is a mental model (as a pun to the large language model) which, you know, you carry this one around with you in your head and use it whenever you need to, no token budget needed...
lol?
O_o
OK, OK, I'll see myself out.
But! Not before we look at some...
Simple(r) illustrations of the translation machine usage
So, where does that leave us when it comes to "how can I employ all of this to make better use of LLMs (the AI) in my work"?
Well, this article has already gotten waaaay longer than I initially intended, and I have dropped a lot of stuff out of it, beleive you me. For that reason, I will give you here a few very general examples that are meant to be taken as a generic templates and not as an exact step-by-step recipe.
The most important takeaway from all of this would be the following:
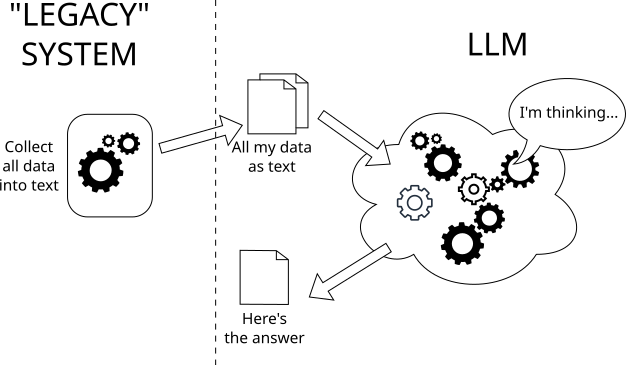
- An LLM is not a thinking machine, in other words don't build your workflow where you offload processing, decision making, problem solving to a large language model hoping it will complete the work. AI agents are a prime example of this.
Don't do this:
- An LLM is a translation machine, in other words use it in your workflows to do the work that it is built for and is really good at. It expands, contracts, shuffles, reorders, translates really well. The key advantage in all of that is that when it, for example, translates an input text into its expanded version, it uses words that really well correspond to the input text. It can expand with words from your corporate documents, project documentation, or just general knowledge scraped from the Internet. Use that to your advantage. Stop chasing ghosts in the machine.
Do this:
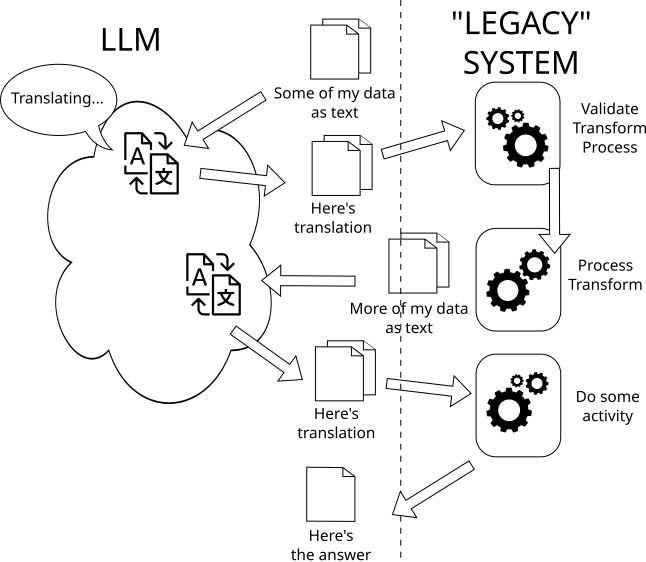
Yes, that looks more involved than just offloading everything to a thinking machine, and listen, once humans invent a thinking machine, we'll do just that: offload all that work to you personal C-3P0 or Commander Data.
In the meantime, you could build a way better and more consistent "AI agents" using the second diagram as a starting thinking point about your work process design. Use your existing systems and processes and APIs and whatnot to guiderail the translation process, and use the output of the translation to direct your existing systems. And don't do it all in one go (a.k.a. I need 1,000,000 token sized context), do it in iterations, translation machines get inevitably lost after you push their translation tree too far.
The simplest use of the translation machine would be to have it translate from natural language into whatever your system uses to query data from your corporate data warehouse or data lake. Have user type (or even say, and you can then transcribe that using something like whisper.cpp) what they want to get out of the data storage system and then LLM will translate that into, for example, a JSON payload for your query API endpoint. The database does its thing and returns bunch of results. Your new query system then collates the returned documents into a new context for your LLM and have it translate that into shorter form, you know, have it summarize all that.
Or, if you have an application that has a lot of buttons, drop downs and forms user needs to fill out in order to get to a report, create a natural language interface for that. User types what they want in natural language and LLM translates that into HTML form data, or whatever your app can already handle.
I worked on a similar web application a handful of years back where user had to go through 4 or 5 steps, each consisting of a bunch of forms, inputs, drop-downs and intermediate query results from which you select constraints for the next stage, it even had a geographical map with domain-specific representation of some of the query data. And then you finally get to the last step and fire off all of that into a monster data lake that would return a report you were doing all that work to get. Then you would go back and tweak the dials and sent another request for updated report. Round and round until you dialed the numbers just where you wanted them. I once jabbed at our PO mid-sentence while he was explaining what they needed on third panel, second form, 15-th dropdown changed: "Wouldn't it be cool if you could just tell the computer to fill all those for you and then you just go to the report screen?". I'll never forget how his eyes lighted up when he sincerely replied: "Can you do that?!". That was just a few years after attention transformers became a thing, and few years before GPT became a public toy. And no, I have no idea what happened to that app, left the company years and years ago.
Those are just the simplest low hanging fruit that you can pick with the translation machine, and people are already doing it. Haven't checked myself, but I did read that "Todoist has a feature that allows you to convert filters on your tasks from natural language" in this colourfully titled article. And that was in 2024. So, you are already late. Do you feal the FOMO yet? Mwhahahah.
The very first steps in using the translation machine IRL in your existing, well established and useful, systems, and ones that will not require you to burn company's quarterly budget on tokens, may be some of these:
- translation of natural language to whatever your backend understands: JSON, API calls, command line parameters, to form queries
- your "legacy" system checks correctnes of the input (syntax), its meaning (semantic) and does the work
- your system produces proper results and LLM then:
- summarizes
- or expands on the output content
- you may add here a predetermined equivalents of "system prompts" to anchor the generated output text
- you can add to context relevant documents that your DB found
- or just converts the machine-readable resutl into natural language in the most optimal way ("simple" translation)
- (human) user of your system then looks at (or listens to, eh?) the response text and decides what to do next
This article is getting way too long as it is (have I already said that?) and I'll not be going into more detailed and in-depth examples. The focus of this article was to present a different model of thinking about what LLMs do and not to elaborate at length how to design systems around that.
I'll leave you with an optional exercise: when you get bored, go and watch this Mo Bitar's video and try and observe all the things said in there through the lenses of it's a translation machine. Having proverbial glasse with those lenses on, to me at least, a number of things said sound a bit silly, and other things, like that you should write very detailed very precise instructions (a.k.a. software specifications/requirements) for a coding agent, sound like a matter of fact, of course it's like that, how else could it be?
Put the glasses on for a while, you don't have to take them as a permanent thing, just try them for a bit, and look at what people are already doing and implementing and, my hope is, you'll find that what I'm saying is not just a pile of goose poop, it might turn out to be something to give you an edge today without bleeding your bank to the token munching monster.
And at the very end, there is of course just one more thing left, and that is, obviously....
What's the deal with this "Magnificent" part in the name?
If you haven't watched The Expanse TV show, I highly recommend you do. It's a hard science fiction show, based on the series of novels by the same name. "Hard science" comes from the way that space travel around our Solar system, and all that goes with it, is portrayed: pretty close to how it would look in real life. The "fiction" part refers to, of course, the narrative, characters and all that, but also to two "sciency" things: aliens (you kind of almost have to have those in a sci-fi genre) and the fusion drive.
In real life, today, we have chemical rocket engines that propel our human space ships and satellites into orbit and around the Solar system. Using state-of-the-art chemical rocket engines it would take anywhere between 3 and 9 months to travel between Earth to Mars (in either direction), and that only on certain date, not any given day, whenever you feel like. And you would be in weightless state, floating around, having issues with the toilet every single day, during the entire months-long jurney.
The imaginary fusion rocket engine from The Expanse sci-fi world is so good and cool, that you can start it up when you take of on your trip to Mars, and then keep it running without pause the whole trip. The only short period when it would not run is at the halfway point when your space ship needs to rotate 180 degrees in order to fire the rocket engine in the opposite direction so you can start reducing the speed you have been building up from accelleration up to that point. So, other than those few minutes while ship is reorienting itself, you would be able to walk, work and live around the ship as if you were on Earth. A rocket engine that works all the time would provide acceleration to everything on the ship, an artificial gravity, that would make it look as if you are not in space. No troubles with the toilet the whole trip. And, check this out, it would take between 2 and 8 days to get to Mars from Earth. Now, that's what I call a fantastic deal. And it is fantastic, because it's just fiction, the fusion drive does not exist in real life, today.
Let's pretend, just for a minute, that we human people have built a fusion drive, a fusion rocket engine just like the one from The Expanse. Let's pretend that something happened a few years back and someone fired up the engine and it worked and now everyone and their grandmother is building and operating one. Wouldn't that be cool? We can now go to Mars in at most 8 days and to Jupiter in a couple of weeks. Moon? Just over 3 hours. Travelling to Moon would be like flying to the next big city on Earth, as far as travel time is concerned. So, we now have this fusion drive and everyone is talking about how human history and civilization will change forever in the next 4-5 years, we just need some time to build all those ships and stuff.
Except, that's not what is happening. Yes, everyone is building ships and talking about space travel. But they are not building ships that look like the ones from The Expanse. No. They are building ships that look like USS Enterprise from Star Trek, or Millenium Falcon from Star Wars. It takes way more effort and material and money. Why are they doing that? Because we are to travel to stars. Humans are to become interstellar species, they say. Travelling between planets? Pffft, trinkets. Don't pay attention to that. We built this fusion drive in measly few years, and it's getting better every year, and very, very soon we will create version of it called the warp drive!! It is just matter of time and money, and if you doubt that just look at the fusion drive!!
So, everyone is building these mega resource demanding and super expensive, very clunky, totally not clumsy to operate, interstellar ships. And they are mounting fusion drive rockets on them so that they can demonstrate how it would work once the warp drive is completed, but in reality it is super convoluted, and did I mention super resource demanding and mega expensive, to operate these things. And, they are pushing everyone to learn interstellar cartography and how to operate interstellar flights and machinery, yet to be invented, designed and built.
Basically, everyone is building this:

while at the same time saying to ignore those quadcopter rotors (which only allow the ship to operate within the Earth's atmosphere) because we are just a year away from building an "ion engine" that will be then mounted onto that Millenium Falcon and it will fly to the Moon.
And I'm watching all of that and wondering: why are we wasting time on building 1:1 replica of USS Enterprise D and Imperial Star Destroyer that will never fly without the warp drive which will never be built? Why aren't we building proper interplanetary space ships that use this fusion drive to expand around Solar system? Or, in the case of that Millenium Falcon quadcopter toy: why aren't we building drones and quadcopters of all shapes and sizes, instead of pretend full-size fictional space ship replica powered by 4 propellers?
I mean, look at the fusion drive! It is not the imaginary warp drive sure, but it is not just a rocket engine either, it's a fusion rocket engine! It's real (in this imaginary metaphorical world I'm describing) and we have it right now! It's a magnificent machine with which we can do fantastic things!!
And that's what it is.
It is not just a translation machine. It is one magnificent translation machine.
At the very minimum, where "for these users, natural language or menu selection seem to be the most viable alternatives" it can implement the "natural language" part, the SEQUEL dream from 50 years ago. And I am pretty much 100% confident you my dear fellow human person, you can do way more than just that using this magnificent translation machine.
Peace.